Teaching Robot How to Stab
Published:
Deep Reinforcement Learning final project.
Introduction
Robotic grasping and manipulation is a large area of active research with many practical applications. One domain in which robotic manipulation can add significant value is in medicine, in which individuals who have lost the use of their limbs can be aided by robotic assistants. In particular, we focus on the sub-problem of grasping and manipulation of food, which is for obvious reasons a primary use-case. Modeling interactions in this domain is challenging because food items are typically deformable. Rather than being rigid bodies that can be grasped (as is common in many manipulation tasks), food items are typically cut, stabbed, or scooped. Our project explored how a robotic agent can use reinforcement learning to learn to manipulate deformable objects of this variety.
To do this, we created a simulated environment containing an agent which controls a robotic arm with a skewer as its end-effector. We placed a simplified representation of food item into this environment, and using policy gradients guided by imitation learning, trained our agent to use the arm to pick up the food in a controlled fashion.
Simulation
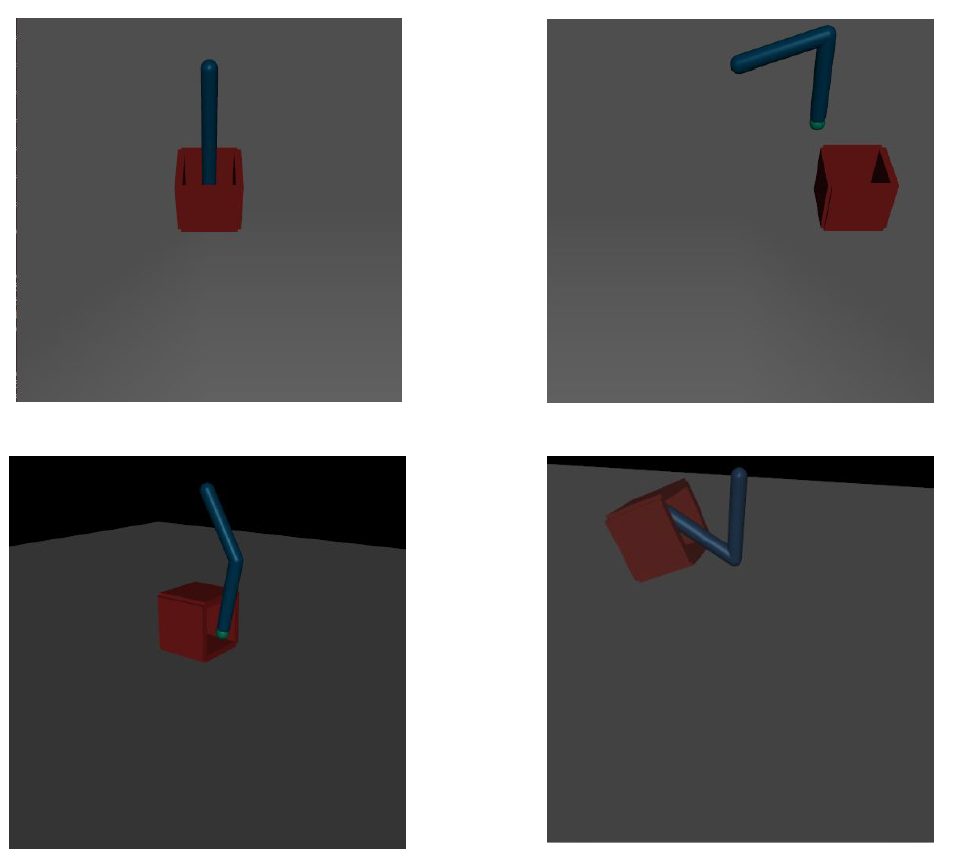 Our environment was developed in the MuJuCo simulator.The state space consisted of 33 features, including the position and velocity of the target and joints. The action space consisted of two continuous values, each between -1 and 1, corresponding to the torque on the two joints of the manipulator arm.
Our environment was developed in the MuJuCo simulator.The state space consisted of 33 features, including the position and velocity of the target and joints. The action space consisted of two continuous values, each between -1 and 1, corresponding to the torque on the two joints of the manipulator arm.
Method
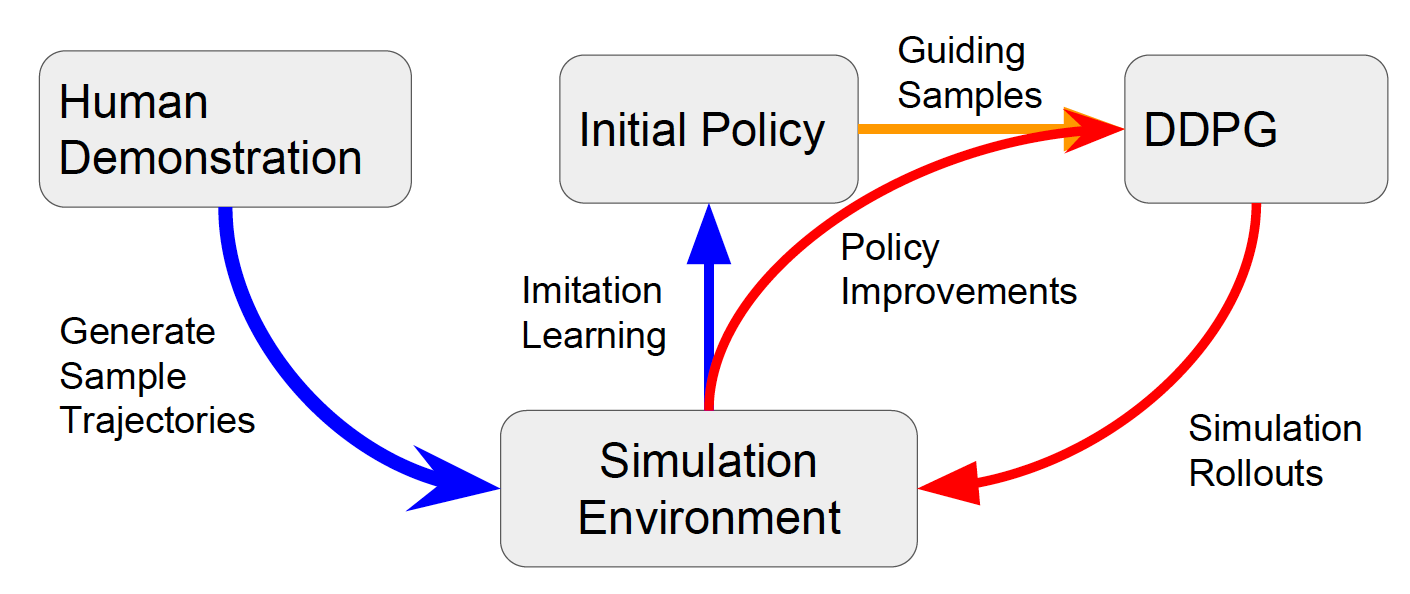 We trained our agent using deep deterministic policy search, guided by imitation learning. First, we manually controlled the simulated arm, and demonstrated 10 trials that obtained the desired behavior. We then trained the network to imitate this behavior. During this phase of training, we used a two-layer feedforward network with 100 neurons per layer. After training in this fashion until convergence (approximately 500 epochs), we saved the policy to initialize the second segment of our training process. Starting from this learned policy, we then re-trained our agent using deep deterministic policy search. During this phase, our agent was modeled using a two-layer feedforward neural network with first layer of size 400 and second layer of size 300. This agent was again trained until convergence, which took approximately 1,000,000 interactions.
We trained our agent using deep deterministic policy search, guided by imitation learning. First, we manually controlled the simulated arm, and demonstrated 10 trials that obtained the desired behavior. We then trained the network to imitate this behavior. During this phase of training, we used a two-layer feedforward network with 100 neurons per layer. After training in this fashion until convergence (approximately 500 epochs), we saved the policy to initialize the second segment of our training process. Starting from this learned policy, we then re-trained our agent using deep deterministic policy search. During this phase, our agent was modeled using a two-layer feedforward neural network with first layer of size 400 and second layer of size 300. This agent was again trained until convergence, which took approximately 1,000,000 interactions.
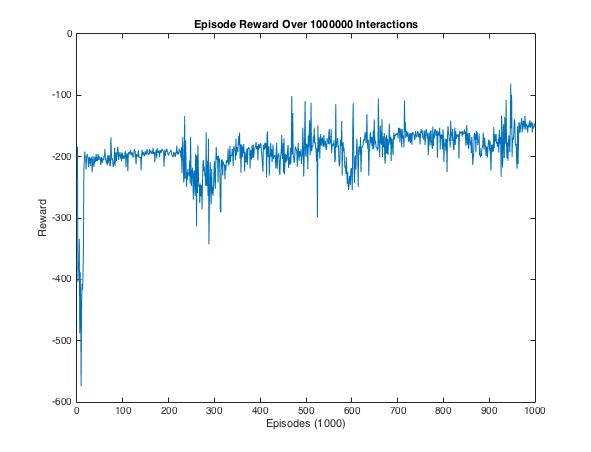
Results:
Here we show the training results of our DDPG network. Training on the initial policy from human demonstration provided a stable baseline approach. However, the small variance in input timing make it difficult for our agent to succeed consistently. The deep deterministic policy gradient helped the policy become more flexible in cases that the demonstrations failed to cover.